
データを分析するとき、中央値を計算したい事ありますよね。
本記事ではpythonでデータの中央値を計算する方法を紹介します。
データを新しく用意するのであればstatistics.median, すでにあるデータの中央値を求める場合はpandas.medianがおすすめです。
pythonで中央値を計算する4つの方法

今回紹介する4つの方法は次のとおりです。それぞれにメリット・デメリットがあります。
| 自作関数 | statistics.median() | numpy.median() | pandas.madian() | |
|---|---|---|---|---|
| メリット | 環境構築の必要がない | 環境を構築しなくて良い コードが簡単 | 行列の中央値を求めることができる | すでにデータがある場合、 操作が簡単 |
| デメリット | 関数を自力で書く必要がある | 行列などの計算はできない | ライブラリのインストールが必要 | ライブラリのインストールが必要 |
それぞれの方法をコードを見ながら確認しましょう。
本記事のコードはグーグルコラボラトリーを使用して、動作を確認しています。
中央値を求める関数を自作する

1つ目は関数を自作して中央値を求める方法です。
プログラミングを動かすにはどうしたらいいか考えたり、if構文やdef文を使用するため、コードを書く練習にもなるでしょう。
また、環境構築に関する知識がなくとも使用可能です。
始めに手計算で中央値を求める際、どのような手順が必要かを確認しましょう。
- データを小さい順に並び替える
- データの中央がどこか探す
- 奇数の場合、データ中央の値を返す
- 偶数の場合、データ中央の値2つの平均を算出する
この手順で実行できれば、中央値を計算可能です。
確認した手順をコードで書いていきます。
文章書いた手順を計算式に書き直してコーディングします。
def cal_med(data):
# 1.データを小さい順に並べる
srt_data = sorted(data)
# 1-1.データの個数の偶奇を判断する
rem = len(srt_data) % 2
#2.中央の場所=データの個数/2 番目
med = int(len(srt_data)/2)
# 3.奇数の場合、データ中央の値を出力する
if rem == 1:
print(srt_data[med])
# 4.偶数の場合、データの中央の値2つの平均を計算
else:
print((srt_data[med] + srt_data[med - 1])/2)中央値を調べたいデータが毎回変わっても使いやすいように、def文で作成し関数として呼び出せるようにします。
コメントアウトで各コードがどのような操作をするか書いていますが、3点ほど詳しく解説します。
1. データの個数の偶奇を判断する
データの個数が奇数の場合と偶数の場合で違う動作をしてほしいので、偶奇を判断する計算式を作成します。
データの個数を2で割った際、余りがあれば奇数、割り切れれば偶数だと判断できます。
データの個数を求めるためにlen()関数を使用し、% 2 は2で割った時の余りの計算です。
2. データの中央を探す
データの中央の場所を探すには、データの個数を2で割れば分かります。
先ほど同様関数len()使って簡単に計算できますが、1点注意が必要です。それは何番目の指定は必ず整数であることです。
そのため、式をint()関数で囲ってあげることで、整数で結果を返すようにします。
3. if構文で各条件での動作を指示する
最後にif構文を使って、データの個数が奇数の場合と偶数の場合とで別の操作を行なうように指示します。
また、リスト[数字]で指定した数字の場所にいるデータを返します。今回だとsrt_data[med]などですね。
remやmedを使わずに計算式を記述しても問題なく動作しますが、コードが読みづらいですし、記述ミスなどで修正したい場合に面倒ですので今回のような書き方をお勧めします。
作成したコードが問題なく実行できるかを実際に使用して試しましょう。
まずはデータを用意します。
#奇数個のデータ
data1 = [20, 9, 95, 66, 12]
#偶数個のデータ
data2 = [21, 14, 16, 63, 77, 52]自作した関数でdata1, data2の中央値を求めてみます。
cal_med(data1)出力:
20
cal_med(data2)出力:
36.5
問題なく動くことが確認できました。
1行のコードで中央値を求める|statistics.median()

統計用ライブラリstatisticsで中央値を求めることができます。
statisticsはpythonに標準で搭載されているライブラリなので、インストール等の必要なく使用可能です。
始めにstatisticsライブラリをインポートします。
import statisticsstatistics.median(リスト)で中央値を算出可能です。
先ほど用意したdata1, data2の計算してみましょう。
statistics.median(data1)出力:
20
statistics.median(data2)出力:
36.5
たったコード1行で実行できました。簡単ですね。
ちなみにデータの個数が偶数の場合、中央となる2つのデータをそのまま求めることも可能です。
小さい方の値が知りたい場合はstatistics.median_low()、大きい方の値が知りたい場合はstatistics.median_high()と記述します。
statistics.median_low(data2)出力:
21
statistics.median_high(data2)出力:
52
行列の中央値を求める|numpy.median()

配列計算ライブラリであるnumpyを使用しても中央値を計算可能です。
numpyを使用することで、行列の中央値が簡単に計算できます。
始めにnumpyをインポートします。
もし使用している環境にnumpyがない場合はインストールが必要です。
グーグルコラボラトリーを使用している場合はすでにnumpyがインストールされているので問題ありません。
# numpyのインストールが必要
import numpy as np計算する行列も用意しましょう。
list_num = np.array([[10, 1, 3, 7, 1, 5], [13, 7, 35, 9 , 6, 4]])
print(list_num)出力:
[[10 1 3 7 1 5]
[13 7 35 9 6 4]]
用意した行列の中央値を計算してみましょう。
np.median(l)出力:
6.5
計算できました。行や列を指定しないと、行列全体の中央値を算出します。
引数axisに0を指定すると各列の中央値、1を指定すると各行の中央値を算出します。
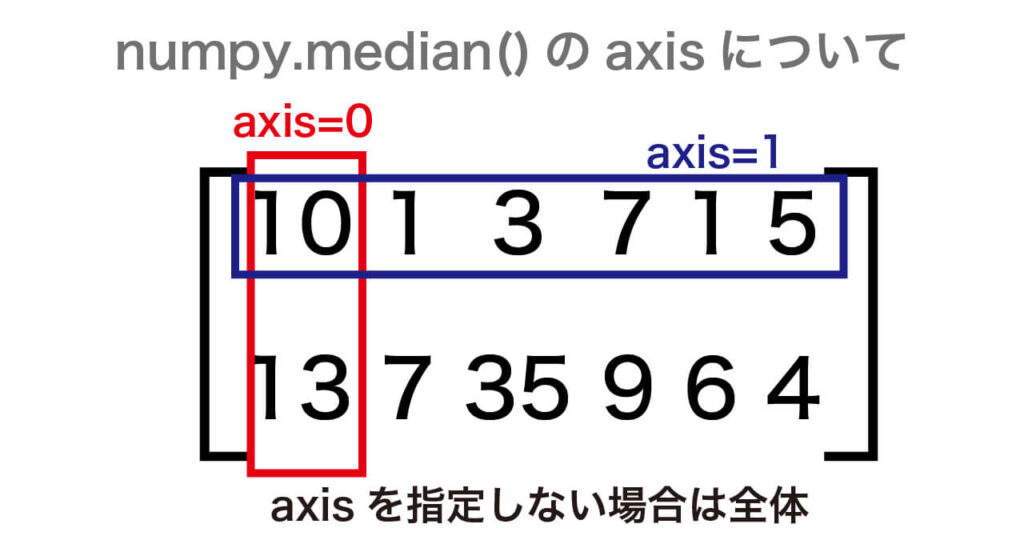
np.median(l, axis=0)出力:
array([11.5, 4. , 19. , 8. , 3.5, 4.5])
np.median(l, axis=1)出力:
array([4., 8.])
既にあるデータを読み込んで中央値を求める|pandas.median()

データ解析ライブラリのpandasを用いることでも中央値が計算できます。
pandas公式ーpandas.DataFrame.median()
エクセルの表などで既にあるデータの中央値を求めたい場合は、その表を読み込んで操作できるpandasが便利です。
データ解析ライブラリのpandasを用いることでも中央値が計算できます。
pandasをインポートします。
また、既にあるデータとして、データ可視化ライブラリseabornに入っているirisデータセットを使用します。
そのためseabornもインポートしましょう。
pandasおよびseabornもnumpy同様インストールの必要があるので気をつけてください。
# pandas, seabornのインストールが必要
import pandas as pd
import seaborn as snsseabornのirisデータセットも読み込んでおきましょう。
df = sns.load_dataset("iris")
df.head()出力:
| index | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
それではirisデータセットの中央値を求めてみましょう。
使い方は データセット.median() です。
df.median()出力:
sepal_length 5.80 sepal_width 3.00 petal_length 4.35 petal_width 1.30 dtype: float64
各列ごとに中央値が返されました。
ちなみに数値以外のデータが入っていたspeciesは無視されています。
行ごとの中央値を求める場合はaxis=1と指定します。
この場合も文字列が入力されているspeciesは無視されます。
df.median(axis=1)出力:
0 2.45
1 2.20
2 2.25
3 2.30
4 2.50
...
145 4.10
146 3.75
147 4.10
148 4.40
149 4.05
Length: 150, dtype: float64
まとめ
今回はpythonでデータの中央値を計算する方法を紹介しました。
使い勝手の点から、データを新しく用意するのであればstatistics.median, すでにあるデータを用意している場合はpandas.medianをおすすめします。
もしこの記事を読んでpythonをもっと勉強したいと持った人は次の記事もオススメです。
pythonを独学で勉強する方法について書いています。








コメント