
データの順番を並び替えたいことってありますよね。
pandasには順番を並び替える関数として、pandas.sort_valuse()とpandas.sort_index()の2つがあります。
本記事ではソート関数の説明と使い方について、例を用いながらわかりやすく解説していきます。
pandas.sort関数について

pandas.sott()は昔のバージョンにあった関数で、新しいバージョンでは使用できません。
代わりにpandas.sort_values()とpandas.sort_index()が用意されています。
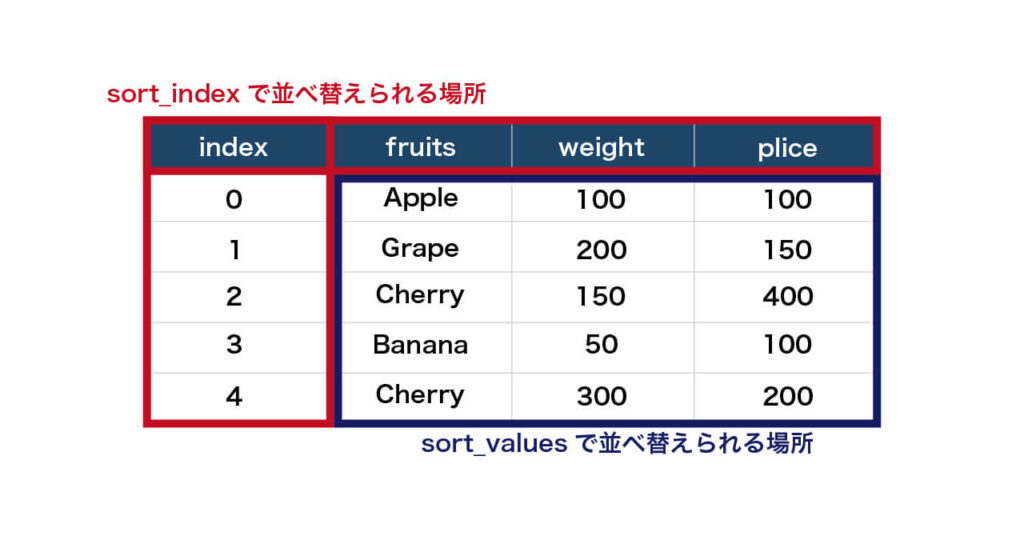
値で並び替えたい場合はpandas.sort_values()、インデックスで並び替えたい時はpandas.sort_index()を使います。
本記事のコードはグーグルコラボラトリーで実行・確認しています。
pandas.sort_values()の使い方

始めにpandas.sort_values()の使い方を見ていきましょう。
準備
始めにpandasライブラリのインポートと、今回使用するDataFrameを用意しましょう。
DataFrameは果物の名前、重さと価格が書かれています。
import pandas as pddf1 = pd.DataFrame({
'fruits': ['Apple', 'Grape', 'Cherry','Banana', 'Cherry'],
'weight': [100, 200, 150, 50, 300],
'plice': [100, 150, 400, 100, 200]
})
df1出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100 | 100 |
| 1 | Grape | 200 | 150 |
| 2 | Cherry | 150 | 400 |
| 3 | Banana | 50 | 100 |
| 4 | Cherry | 300 | 200 |
基本的な使い方
pandas.sort_valuesは指定した軸に沿って並べ替えます。
ソートしたい列名を指定することで使用可能です。df1を果物の名前で並べ替えてみましょう。
df1.sort_values('fruits')出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100 | 100 |
| 3 | Banana | 50 | 100 |
| 2 | Cherry | 150 | 400 |
| 4 | Cherry | 300 | 200 |
| 1 | Grape | 200 | 150 |
‘fruits’列の昇順(A→Z)に沿ってデータが並び変わりました。
pandas.sort_valuesは複数の列を指定してソートすることも可能です。果物名と価格の2つを指定してみましょう。
複数の列名でソートしたい時は、リストで指定してください。
df1.sort_values(['fruits', 'plice'])出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100 | 100 |
| 3 | Banana | 50 | 100 |
| 4 | Cherry | 300 | 200 |
| 2 | Cherry | 150 | 400 |
| 1 | Grape | 200 | 150 |
‘fruits’ のソート条件が最優先されて、2つデータがあるCherryの順番が ‘plice’の値によって並び替えられました。
指定する列名の順番を変えたらどうなるでしょう?
df1.sort_values(['plice', 'fruits'])出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100 | 100 |
| 3 | Banana | 50 | 100 |
| 1 | Grape | 200 | 150 |
| 4 | Cherry | 300 | 200 |
| 2 | Cherry | 150 | 400 |
‘price’のソートが最優先されて、同じ値であるAppleとBananaが’fruits’でソートされました。
左側に指定した列名が優先されていますね。
pandas.sort_valuesの引数
ここからはpandas.sort_values()で使用可能な引数について説明していきます。
並び替える軸の指定: axis
pandas.sort_values()は指定した列に沿ってソートする関数だと説明しました。
もし行に沿って並べ替えたい場合、引数axisが便利です。
axis=1を指定すると、指定した行に沿って並べ替えます。
df1の行と列を入れ替えて(転置して)、axisを試してみましょう。
df1_T = df1.T
df1_T出力:
| index | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| fruits | Apple | Grape | Cherry | Banana | Cherry |
| weight | 100 | 200 | 150 | 50 | 300 |
| plice | 100 | 150 | 400 | 100 | 200 |
df1の表と列が入れ替わりました。
df1_T.sort_values('fruits', axis=1)出力:
| index | 0 | 3 | 2 | 4 | 1 |
|---|---|---|---|---|---|
| fruits | Apple | Banana | Cherry | Cherry | Grape |
| weight | 100 | 50 | 150 | 300 | 200 |
| plice | 100 | 100 | 400 | 200 | 150 |
行名 ‘fruits’ に沿ってソートされたことが確認できます。
昇順・降順の指定: ascending
並び替えはデフォルトで昇順 (1→9, A→Z)に設定されています。
ascending=Falseとすると降順 (9→1, Z→A)でソートされます。
df1.sort_values('fruits', ascending=False)出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 1 | Grape | 200 | 150 |
| 2 | Cherry | 150 | 400 |
| 4 | Cherry | 300 | 200 |
| 3 | Banana | 50 | 100 |
| 0 | Apple | 100 | 100 |
もとのDataFrameを変更: inplace
引数inplaceをTrueとするとソートされた結果を元のDataFrameに反映します。
元のDataFrameを変更してしまうと修正したいときに手間なので、使用時は注意しましょう。
欠損値(NaN)のソート条件の指定: na_position
指定した列に空白 (欠損値, NaN)が含まれている場合、デフォルトでは最後にソートされます。
df1の ‘weight’ にNaNを用意して確認してみます。
df1_nan = df1.copy()
df1_nan.iloc[2, 1] = pd.np.nan
df1_nan 出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100.0 | 100 |
| 1 | Grape | 200.0 | 150 |
| 2 | Cherry | NaN | 400 |
| 3 | Banana | 50.0 | 100 |
| 4 | Cherry | 300.0 | 200 |
df1_nan.sort_values('weight')出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 3 | Banana | 50.0 | 100 |
| 0 | Apple | 100.0 | 100 |
| 1 | Grape | 200.0 | 150 |
| 4 | Cherry | 300.0 | 200 |
| 2 | Cherry | NaN | 400 |
na_position=firstとするとNaNが先頭に並べられます。
df1_nan.sort_values('weight', na_position='first')出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 2 | Cherry | NaN | 400 |
| 3 | Banana | 50.0 | 100 |
| 0 | Apple | 100.0 | 100 |
| 1 | Grape | 200.0 | 150 |
| 4 | Cherry | 300.0 | 200 |
indexの振り直し: ignore_index
indexはDataFrame作成時に割り振られるため、ソートするとそれに合わせた順番になってしまいます。
ignore_index=Trueと指定することで、インデックスの振り直しが可能です。
df1.sort_values('fruits', ignore_index=True)出力:
| index | fruits | weight | plice |
|---|---|---|---|
| 0 | Apple | 100 | 100 |
| 1 | Banana | 50 | 100 |
| 2 | Cherry | 150 | 400 |
| 3 | Cherry | 300 | 200 |
| 4 | Grape | 200 | 150 |
pandas.sort_index()の使い方

pandas.sort_indexはインデックスを参照してソートする関数です。
準備
始めにDataFrameを準備します。
indexをバラバラに設定したいため、先ほどと記述方法を変えてDataFrameを作成します。
d = [['Apple', 100, 100], ['Grape', 200, 150], ['Cherry', 150, 400], ['Banana', 50, 100], ['Cherry', 300, 200]]
df2 = pd.DataFrame(
data=d,
index=[3, 5, 1, 4, 2],
columns=['fuits', 'weight', 'plice']
)
df2出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 3 | Apple | 100 | 100 |
| 5 | Grape | 200 | 150 |
| 1 | Cherry | 150 | 400 |
| 4 | Banana | 50 | 100 |
| 2 | Cherry | 300 | 200 |
基本的な使い方
ソートしたいDataFrameの後ろに.sort_index() を記述するだけで、indexに沿ってデータが並び替えられます。
df2.sort_index()出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 1 | Cherry | 150 | 400 |
| 2 | Cherry | 300 | 200 |
| 3 | Apple | 100 | 100 |
| 4 | Banana | 50 | 100 |
| 5 | Grape | 200 | 150 |
pandas.sort_indexの引数
.sort_index()の引数を紹介します。.sort_values()と同じものが多いです。
並び替える軸を指定する: axis
引数axisに1を指定することで、列を並べ替えます。
df2.sort_index(axis=1)出力:
| index | fuits | plice | weight |
|---|---|---|---|
| 3 | Apple | 100 | 100 |
| 5 | Grape | 150 | 200 |
| 1 | Cherry | 400 | 150 |
| 4 | Banana | 100 | 50 |
| 2 | Cherry | 200 | 300 |
ここで注意したいのは、.sort_index()のaxis引数は列自体の並び替えになることです。
上の結果で言うと、列が列名の頭文字に沿ってソートされています。
昇順・降順の指定: ascending
引数ascendingをFalseと記述すると、降順でソートされます。
df2.sort_index(ascending=False)出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 5 | Grape | 200 | 150 |
| 4 | Banana | 50 | 100 |
| 3 | Apple | 100 | 100 |
| 2 | Cherry | 300 | 200 |
| 1 | Cherry | 150 | 400 |
元のDataFrameを変更: inplace
引数inplaceをTrueとするとソートされた結果を元のDataFrameに反映します。
元のDataFrameを変更してしまうと修正したいときに手間なので、使用時は注意しましょう。
欠損値(NaN)のソートの指定: na_position
NaNが含まれるインデックスをソートするとNaNは最後にソートされます。
df2_nan = pd.DataFrame(
data=d,
index=[3, 5, 1, pd.np.nan, 2],
columns=['fuits', 'weight', 'plice'])
df2_nan出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 3.0 | Apple | 100 | 100 |
| 5.0 | Grape | 200 | 150 |
| 1.0 | Cherry | 150 | 400 |
| NaN | Banana | 50 | 100 |
| 2.0 | Cherry | 300 | 200 |
df2_nan.sort_index()出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 1.0 | Cherry | 150 | 400 |
| 2.0 | Cherry | 300 | 200 |
| 3.0 | Apple | 100 | 100 |
| 5.0 | Grape | 200 | 150 |
| NaN | Banana | 50 | 100 |
pandas.sort_values()同様、引数np_positionでNaNのソート条件を変更可能です。
df2_nan.sort_index(na_position='first')出力:
| index | fuits | weight | plice |
|---|---|---|---|
| NaN | Banana | 50 | 100 |
| 1.0 | Cherry | 150 | 400 |
| 2.0 | Cherry | 300 | 200 |
| 3.0 | Apple | 100 | 100 |
| 5.0 | Grape | 200 | 150 |
indexの振り直し: ignore_index
pandas.sort_indexでもソート後のindexを振り直すignore_indexが使用可能です。
引数ascendingやNaNが含まれるDataFrameで使用するといいでしょう。
df2nan.sort_index(ignore_index=True)出力:
| index | fuits | weight | plice |
|---|---|---|---|
| 0 | Cherry | 150 | 400 |
| 1 | Cherry | 300 | 200 |
| 2 | Apple | 100 | 100 |
| 3 | Grape | 200 | 150 |
| 4 | Banana | 50 | 100 |
まとめ
今回はデータの順番を並べ替えるpandas.sort_valuesとpandas_sort_indexについて紹介しました。
基本的にはどちらも似たような引数を持っていますが、axisは異なった結果になるので注意が必要です。
この記事を読んでPythonを勉強したいと思った人はこちらの記事もご覧ください。Pythonを独学する方法を紹介しています。








コメント