
pyhtonでデータ分析をする際にデータの最大値や最小値を求めたいことがありますよね。
この記事ではpythonで最大値・最小値を計算する方法を紹介します。
pythonで最大値・最小値を計算する方法
pythonで最大値を計算する方法は、
- max(), min()
- numpy.amax(), numpy.amin()
- pandasライブラリ
簡単に最大値・最小値を計算する: max(), min()

最も簡単に最大値、最小値を計算する方法はmax(), min()です。括弧の中のリストからmax()であれば最大値、min()であれば最小値を返します。
score = [51, 70, 35, 90]
print(max(score))
print(min(score))出力: 90
35
ちなみに数字たけでなく、アルファベットに対しても最大・最小が適応されます。アルファベットの場合、aが最小、zが最大となります。
print(max('score'))
print(min('score'))出力: s
c
配列全体の最大値、最小値を求める: numpy.amax(), numpy.amin()

配列全体の最大値、最小値を計算したい場合、numpy.amax(), numpy.amin()を使います。numpyライブラリのインストールが必要です。ちなみにnumpy.max(), numpy.min()と記述してもamax(),amin()と同様に動きます。
# 事前準備:pythonにnumpyをインストールする
import numpy as np
score = np.array([[51, 70, 35, 90],
[21, 0, 55, 50],
[14, 74, 23, 67]])
print(np.amax(score))
print(np.amin(score))出力: 90
0
numpyをimportする際、npと略して使用する事が多いです。
行列に欠損値がある場合: numpy.nanmax(), numpy.nanmin()
行列に欠損値(Not a Number: NaN)がある場合、numpy.max(), nnumpy.min()では計算できません。正確にはnanが返ってきてしまい、最大値・最小値が分かりません。
# 事前準備:pythonにnumpyをインストールする
import numpy as np
print(np.max([[51, 70, 35, 90],
[21, np.nan, 55, 50],
[14, 74, 23, 67]]))
print(np.min([[51, 70, 35, 90],
[21, np.nan, 55, 50],
[14, 74, 23, 67]]))出力: nan
nan
この問題はnumpy.nanmax(), numpy.nanmin()を使うことで解決できます。
# 事前準備:pythonにnumpyをインストールする
import numpy as np
print(np.nanmax([[51, 70, 35, 90],
[21, np.nan, 55, 50],
[14, 74, 23, 67]]))
print(np.nanmin([[51, 70, 35, 90],
[21, np.nan, 55, 50],
[14, 74, 23, 67]]))出力: 90.0
21.0
2つの配列を比較して最大・最小を求める: numpy.maximun(), numpy.minimum()
2つの配列を比較して、各要素ごとの最大値・最小値を求めたい場合、numpy.maximum(), numpy.minimum()を使います。
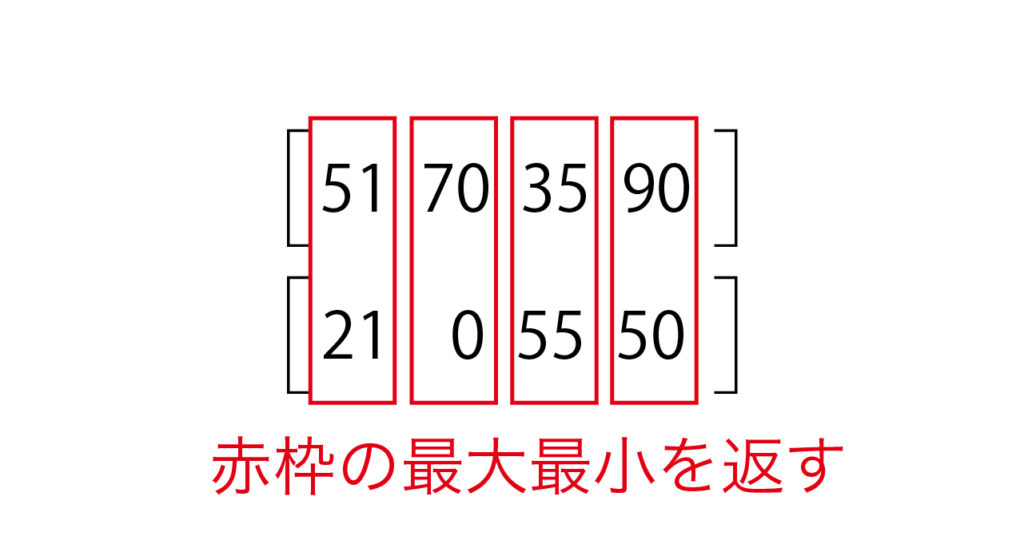
# 事前準備:pythonにnumpyをインストールする
import numpy as np
print(np.maximum([51, 70, 35, 90], [21, 0, 55, 50]))
print(np.minimum([51, 70, 35, 90], [21, 0, 55, 50]))出力: [51 70 55 90]
[21 0 35 50]
pumpy.maximumでNaNを返してほしくない: numpy.fmax(), numpy.fmin()
NaNが含まれる配列でnumpy.maximum(), numpy.minimum()を使った場合、NaNを含んだ配列が返ってきます。
# 事前準備:pythonにnumpyをインストールする
import numpy as np
print(np.maximum([51, 70, 35, 90], [21, np.nan, 55, 50]))
print(np.minimum([51, 70, 35, 90], [21, np.nan, 55, 50]))出力: [51. nan 55. 90.]
[21. nan 35. 50.]
もし数値が入っている要素を返してほしいのであれば、numpy.fmax(), numpy.fmin()を使用しましょう。
# 事前準備:pythonにnumpyをインストールする
import numpy as np
print(np.fmax([51, 70, 35, 90], [21, 0, 55, 50]))
print(np.fmin([51, 70, 35, 90], [21, 0, 55, 50]))出力: [51 70 55 90]
[21 0 35 50]
表ファイルの最大値・最小値を求める: pandasライブラリ

excelやcsvのような表ファイルが既にあって、最大値や最小値を求めたい場合、pandasライブラリが便利です。pandasはpythonでデータを快適に分析するために作られたオープンソースのツールです。numpyライブラリ同様pythonへのインストールが必要です。
pandasで最大値・最小値を求める場合、最初に読み込んだ表ファイルを変数に入れる必要があります。また、データの読み込みにはディレクトリについて理解してしていないとつまずく事があります。
今回はirisデータセットを使用します。このデータセットは「あやめ」という花のがく片と花びらの長さ、幅を品種ごとにまとめたデータです。
# 事前準備:pythonにpandasをインストールする
import pandas as pd
df = pd.read_csv("iris_dataset.csv")
df.head()出力:
| index | Unnamed: 0 | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|---|
| 0 | 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
pandasはインポートする際、pdと省略する事が多いです。
irisデータセットの初め5行を確認しました。(indexとUnnamed: 0はデータナンバーのため無視します。)
それではpandasで最大値・最小値を求めてみましょう。
# 事前準備:pythonにpandasをインストールする
import pandas as pd
df = pd.read_csv("iris_dataset.csv")
print(df.max())
print(df.min())出力:
Max
Unnamed: 0 149
sepal_length 7.9
sepal_width 4.4
petal_length 6.9
petal_width 2.5
species virginica
dtype: object
Min
Unnamed: 0 0
sepal_length 4.3
sepal_width 2.0
petal_length 1.0
petal_width 0.1
species setosa
dtype: object
pandasを使う場合、各列ごとに最大値・最小値を調べてくれます。
最大値や最小値をまとめて算出: describe()
表データの列ごとの最大値や最小値を一度で調べたい場合、describe()を使いましょう。describe()はデータ数・平均・最大値・最小値・標準偏差・四辺位数といった記述統計を返す関数です。表データのおおまかな内容が把握できます。
# 事前準備:pythonにpandasをインストールする
import pandas as pd
df = pd.read_csv("iris_dataset.csv")
df.describe()出力:
| index | Unnamed: 0 | sepal_length | sepal_width | petal_length | petal_width |
|---|---|---|---|---|---|
| count | 150.0 | 150.0 | 150.0 | 150.0 | 150.0 |
| mean | 74.5 | 5.843333333333334 | 3.0573333333333337 | 3.7580000000000005 | 1.1993333333333336 |
| std | 43.445367992456916 | 0.828066127977863 | 0.4358662849366982 | 1.7652982332594662 | 0.7622376689603465 |
| min | 0.0 | 4.3 | 2.0 | 1.0 | 0.1 |
| 25% | 37.25 | 5.1 | 2.8 | 1.6 | 0.3 |
| 50% | 74.5 | 5.8 | 3.0 | 4.35 | 1.3 |
| 75% | 111.75 | 6.4 | 3.3 | 5.1 | 1.8 |
| max | 149.0 | 7.9 | 4.4 | 6.9 | 2.5 |
まとめ
今回はpythonで最大値・最小値を計算する方法を紹介しました。
それぞれ使用できる状況が異なるので、使い分けができるようになりましょう。








コメント